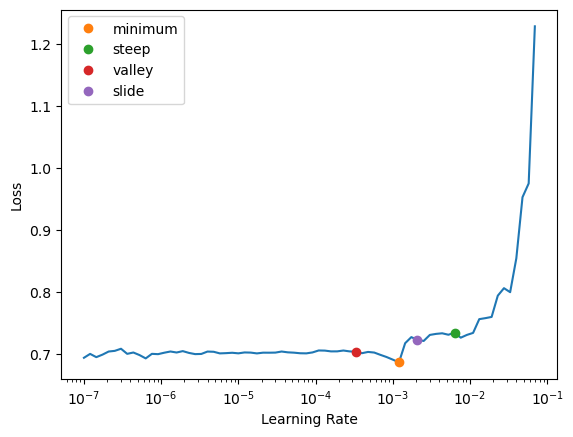
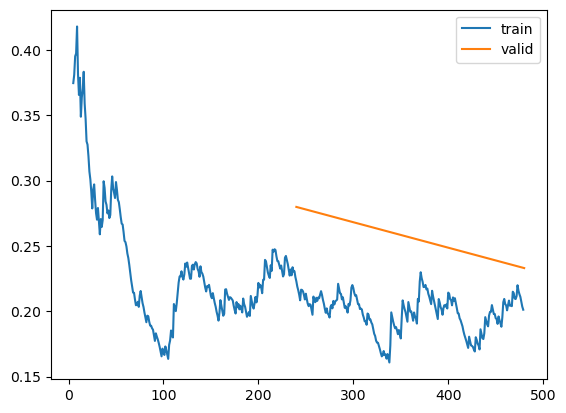
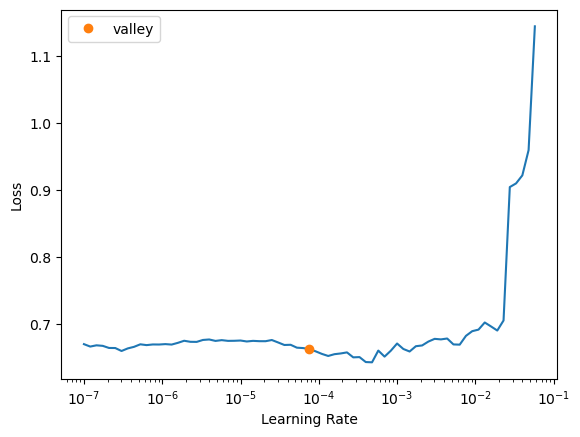
The text.modeling.core module contains core custom models, loss functions, and a default layer group splitter for use in applying discriminiative learning rates to your Hugging Face models trained via fastai
Same as nn.Module, but no need for subclasses to call super().__init__
Type
Default
Details
hf_model
PreTrainedModel
Your Hugging Face model
output_hidden_states
bool
False
If True, hidden_states will be returned and accessed from Learner
output_attentions
bool
False
If True, attentions will be returned and accessed from Learner
hf_model_kwargs
dict
{}
Any additional keyword arguments you want passed into your models forward method
Note that BaseModelWrapper includes some nifty code for just passing in the things your model needs, as not all transformer architectures require/use the same information.
Basic class handling tweaks of the training loop by changing a Learner in various events
Type
Default
Details
base_model_wrapper_kwargs
dict
{}
Additional keyword arguments passed to BaseModelWrapper
We use a Callback for handling the ModelOutput returned by Hugging Face transformers. It allows us to associate anything we want from that object to our Learner.
Note that your Learner’s loss will be set for you only if the Hugging Face model returns one and you are using the PreCalculatedLoss loss function.
Also note that anything else you asked the model to return (for example, last hidden state, etc..) will be available for you via the blurr_model_outputs property attached to your Learner. For example, assuming you are using BERT for a classification task … if you have told your BaseModelWrapper instance to return attentions, you’d be able to access them via learn.blurr_model_outputs['attentions'].
Example
Below demonstrates how to setup your pipeline for a sequence classification task (e.g., a model that requires a single text input) using the mid, high, and low-level API
I wanted to see this movie ever since it was first advertised on TV. I went to Tinsel Town to see it Last Night at 7:40. I regret the day that wasted my ticket on this trash when I could of saw something better. The beginning was all a bunch sex trash and cliches. They exaggerated the way love works in reality. All of the girls were stereo types. The boyfriend was too stupid for his own age. The passing gases that the pregnant girl kept having barely got any laughs. The bank robbery was completely boring with gags that have been used in other movies. Their getaway car was an old beat up Ch...
0
False
1
As a huge baseball fan, my scrutiny of this film is how realistic it appears. Dennis Quaid had all of the right moves and stances of a major league pitcher. It is a fantastic true story told with just a little too much "Disney" for my taste.
1
False
2
This ranks as one of the worst movies I've seen in years. Besides Cuba and Angie, the acting is actually embarrassing. Wasn't Archer once a decent actress? What happened to her? The action is decent but completely implausible. The make up is so bad it's worth mentioning. I mean, who ever even thinks about the makeup in a contemporary feature film. Someone should tell the make up artist, and the DOP that you're not supposed to actually see it. The ending is a massive disappointment - along the lines of "and then they realized it was all a dream"<br /><br />Don't waste your time or your mone...
0
False
3
For those of us Baby Boomers who arrived too late on the scene to appreciate James Dean et. al., Martin Sheen showed us The Way in this great feature.<br /><br />The premise is easy enough: cool hood meets small town sheriff and All-Hell ensues, but the nuts and bolts of this movie enthrall the car nut in all of us. <br /><br />No, this isn't Casablanca, nor is it great Literature, but it IS a serious movie about cars, rebellion, and the genius that is Martin Sheen.<br /><br />Enjoy this and appreciate it for what it is, and for what Martin will become. I loved this movie growing up as a t...
1
False
4
Similar to "On the Town," this musical about sailors on shore leave falls short of the later classic in terms of pacing and the quality of the songs, but it has its own charms. Kelly has three fabulous dance routines: one with Jerry the cartoon mouse of "Tom and Jerry" fame, one with a little girl, and a fantasy sequence where he is a Spanish lover determined to reach his lady on a high balcony. Sinatra, playing Kelly's shy, inexperienced buddy, and Grayson, the woman who serves as the love interest for both men, do most of the singing. Iturbi provides some fine piano playing. At nearly tw...
My Comments for VIVAH :- Its a charming, idealistic love story starring Shahid Kapoor and Amrita Rao. The film takes us back to small pleasures like the bride and bridegroom's families sleeping on the floor, playing games together, their friendly banter and mutual respect. Vivah is about the sanctity of marriage and the importance of commitment between two individuals. Yes, the central romance is naively visualized. But the sneaked-in romantic moments between the to-be-married couple and their
pos
1
WWE Armageddon, December 17, 2006 -- Live from Richmond Coliseum, Richmond, VA <br /><br />Kane vs. MVP in an Inferno match: So this is the fourth ever inferno match in the WWE and it is Kane vs. MVP (wonder why was it the first match on the card). I only viewed the ending parts where Kane sets MVP's ass on fire as they're on the apron and then MVP is running around the arena while yelling eventually the refs put out the fire with a fire extinguisher as MVP sprawls around the entrance ramp. F
pos
Training
.to_fp16() requires a GPU so had to remove for tests to run on github. Let’s check that we can get predictions.
Haha, what a great little movie! Wayne Crawford strikes again, or rather this was his first big strike, a deliriously entertaining little ball of manic kitsch energy masquerading as a psycho killer movie. It's actually a **brilliant** satire on post-hippie American culture in flyover country, though the movie was actually filmed independently in Miami. It defies any kind of studio oriented convention or plot device that I can think of: SOMETIMES AUNT MARTHA DOES DREADFUL THINGS may not be a ver
pos
pos
1
Most would agree that the character of Wolverine is one of the most intriguing characters in comic book history. I'm no Marvel expert, but I did grow up with the adventures of the X-Men and definitely approved of Hugh Jackman's now widely known portrayal of the scruffy Logan. I enjoyed the first X-Men, found the sequel too heavy and messy and liked the third one as comic book entertainment. All through the three movies, I probably enjoyed Jackman more than anything else. I figured the idea of m
Haha, what a great little movie! Wayne Crawford strikes again, or rather this was his first big strike, a deliriously entertaining little ball of manic kitsch energy masquerading as a psycho killer movie. It's actually a **brilliant** satire on post-hippie American culture in flyover country, though the movie was actually filmed independently in Miami. It defies any kind of studio oriented convention or plot device that I can think of: SOMETIMES AUNT MARTHA DOES DREADFUL THINGS may not be a ver
pos
pos
1
Most would agree that the character of Wolverine is one of the most intriguing characters in comic book history. I'm no Marvel expert, but I did grow up with the adventures of the X-Men and definitely approved of Hugh Jackman's now widely known portrayal of the scruffy Logan. I enjoyed the first X-Men, found the sequel too heavy and messy and liked the third one as comic book entertainment. All through the three movies, I probably enjoyed Jackman more than anything else. I figured the idea of m
neg
neg
Prediction
We need to replace fastai’s Learner.predict method with the one above which is able to work with inputs that are represented by multiple tensors included in a dictionary.
Though not useful in sequence classification, we will also add a blurr_generate method to Learner that uses Hugging Face’s PreTrainedModel.generate for text generation tasks.
For the full list of arguments you can pass in see here. You can also check out their “How To Generate” notebook for more information about how it all works.
Haha, what a great little movie! Wayne Crawford strikes again, or rather this was his first big strike, a deliriously entertaining little ball of manic kitsch energy masquerading as a psycho killer movie. It's actually a **brilliant** satire on post-hippie American culture in flyover country, though the movie was actually filmed independently in Miami. It defies any kind of studio oriented convention or plot device that I can think of: SOMETIMES AUNT MARTHA DOES DREADFUL THINGS may not be a ver
pos
pos
1
Most would agree that the character of Wolverine is one of the most intriguing characters in comic book history. I'm no Marvel expert, but I did grow up with the adventures of the X-Men and definitely approved of Hugh Jackman's now widely known portrayal of the scruffy Logan. I enjoyed the first X-Men, found the sequel too heavy and messy and liked the third one as comic book entertainment. All through the three movies, I probably enjoyed Jackman more than anything else. I figured the idea of m
neg
neg
learn.blurr_predict("This was a really good movie")
learn.export(fname=f"{export_fname}.pkl")inf_learn = load_learner(fname=f"{export_fname}.pkl")inf_learn.blurr_predict("This movie should not be seen by anyone!!!!")
Watching Stranger Than Fiction director Marc Forster's The Kite Runner is the cinematic equivalent of eating your vegetables because this art-house epic rated PG-13 is good for your movie-going diet. No, this isn't the kind of movie that I like to slouch on the couch and eyeball at the end of a tough day. The Kite Runner isn't your typical mainstream movie designed to entertain you and make you forget about your troubles. First, no celebrity stars appear in it. Second, nothing is cut and dried,
1
1
1
As an ancient movie fan, I had heard much about the controversial movie CALIGULA assessed ambiguously as one of the most realistic epics by some and as one of the most disgusting porn movies by others. I decided to see it in the entire uncut version to evaluate it myself hoping to find something positive that would make justice to the many accusations towards the film. I sat down in my chair one autumn evening and started to watch. The beginning quotation from the New Testament shocked me a bit
learn.export(fname=f"{export_fname}.pkl")inf_learn = load_learner(fname=f"{export_fname}.pkl")inf_learn.blurr_predict("This movie should not be seen by anyone!!!!")
Thanks to the TextDataLoader, there isn’t really anything you have to do to use plain ol’ PyTorch or fast.ai Datasets and DataLoaders with Blurr. Let’s take a look at fine-tuning a model against Glue’s MRPC dataset …
Spansion products are to be available from both AMD and Fujitsu, AMD said. Spansion Flash memory solutions are available worldwide from AMD and Fujitsu.
equivalent
equivalent
1
However, EPA officials would not confirm the 20 percent figure. Only in the past few weeks have officials settled on the 20 percent figure.
not_equivalent
not_equivalent
Tests
The tests below to ensure the core training code above works for all pretrained sequence classification models available in Hugging Face. These tests are excluded from the CI workflow because of how long they would take to run and the amount of data that would be required to download.
Note: Feel free to modify the code below to test whatever pretrained classification models you are working with … and if any of your pretrained sequence classification models fail, please submit a github issue (or a PR if you’d like to fix it yourself)