This notebook demonstrates how we can use Blurr to train, or fine-tune, a causal language model against examples defined in individual files (similar to how the raw wiki-103 data comes). We demonstrate how to use get_text_files and create a custom splitter function to build our train and validation datasets.
Aquecimento global é o processo de aumento da temperatura média dos oceanos e da atmosfera da Terra causado por massivas emissões de gases que intensificam o efeito estufa, originados de uma série de atividades humanas, especialmente a queima de combustíveis fósseis e mudanças no uso da terra, como o desmatamento, bem como de várias outras fontes secundárias. Essas causas são um produto direto da explosão populacional, do crescimento econômico, do uso de tecnologias e fontes de energia poluidor
ecimento global é o processo de aumento da temperatura média dos oceanos e da atmosfera da Terra causado por massivas emissões de gases que intensificam o efeito estufa, originados de uma série de atividades humanas, especialmente a queima de combustíveis fósseis e mudanças no uso da terra, como o desmatamento, bem como de várias outras fontes secundárias. Essas causas são um produto direto da explosão populacional, do crescimento econômico, do uso de tecnologias e fontes de energia poluidoras e
1
Os astecas eram uma cultura mesoamericana que floresceu no centro do México no período pós-clássico, de 1300 a 1521. Os povos astecas incluíam diferentes grupos étnicos do México central, particularmente aqueles grupos que falavam a língua náuatle e dominaram grandes partes da Mesoamérica entre os séculos XIV ao XVI. A cultura asteca era organizada em cidades-Estados ( " altepetl " ), algumas das quais se juntaram para formar alianças, confederações políticas ou impérios. O Império As
astecas eram uma cultura mesoamericana que floresceu no centro do México no período pós-clássico, de 1300 a 1521. Os povos astecas incluíam diferentes grupos étnicos do México central, particularmente aqueles grupos que falavam a língua náuatle e dominaram grandes partes da Mesoamérica entre os séculos XIV ao XVI. A cultura asteca era organizada em cidades-Estados ( " altepetl " ), algumas das quais se juntaram para formar alianças, confederações políticas ou impérios. O Império Astec
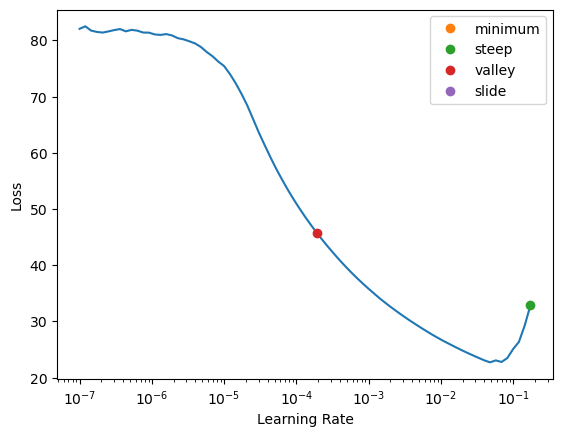
learn.lr_find(suggest_funcs=[minimum, steep, valley, slide])
/home/wgilliam/miniconda3/envs/blurr/lib/python3.9/site-packages/fastai/callback/schedule.py:269: UserWarning: color is redundantly defined by the 'color' keyword argument and the fmt string "ro" (-> color='r'). The keyword argument will take precedence.
ax.plot(val, idx, 'ro', label=nm, c=color)
A Idade Média ( adj. medieval ) é um período da história da Europa entre os séculos V e XV. Inicia-se com a Queda do Império Romano do Ocidente e termina durante a transição para a Idade Moderna. A Idade Média é o período intermédio da divisão clássica da História ocidental em três períodos : a Antiguidade, Idade Média e Idade Moderna, sendo frequentemente dividido em Alta e Baixa Idade Média.\nDurante a Alta Idade Média verifica-se a continuidade dos processos de despovoamento, regressão urbana
Idade Média ( adj. medieval ) é um período da história da Europa entre os séculos V e XV. Inicia-se com a Queda do Império Romano do Ocidente e termina durante a transição para a Idade Moderna. A Idade Média é o período intermédio da divisão clássica da História ocidental em três períodos : a Antiguidade, Idade Média e Idade Moderna, sendo frequentemente dividido em Alta e Baixa Idade Média.\nDurante a Alta Idade Média verifica-se a continuidade dos processos de despovoamento, regressão urbana,
aade dedia é o. & & é u �íodo de �ória da Id,re os �éculos X. V,\nicialisse ao �úa, Estério daano, Sulcidente, aou aante o sumissção de a Europaade Méa.\n Idade Média fo a período daaédio de Europaisão daássica, Europaória,uidental. queês estíodos. a Idiguidade, aade Média, Idade Méa. ao aemente aido em �enteç aixa,ade,dia,\nAante o Idta,ade Média,dou-se aoarade de �os de estó eo e aando ebana, a aasão�es deritsicnicas,iciaadas.ante a Idiguidade Méambin,\n �cados doárbaras deam avos,os de comenado
1
Itália ( ), oficialmente República Italiana, é uma república parlamentar unitária localizada no centro-sul da Europa. Ao norte, faz fronteira com França, Suíça, Áustria e Eslovênia ao longo dos Alpes. A parte sul consiste na totalidade da península Itálica, Sicília, Sardenha, as duas maiores ilhas no mar Mediterrâneo, e muitas outras ilhas menores ficam no entorno do território italiano. Os Estados independentes de San Marino e do Vaticano são enclaves no interior da Itália, enquanto Campione d
ália ( ), oficialmente República Italiana, é uma república parlamentar unitária localizada no centro-sul da Europa. Ao norte, faz fronteira com França, Suíça, Áustria e Eslovênia ao longo dos Alpes. A parte sul consiste na totalidade da península Itálica, Sicília, Sardenha, as duas maiores ilhas no mar Mediterrâneo, e muitas outras ilhas menores ficam no entorno do território italiano. Os Estados independentes de San Marino e do Vaticano são enclaves no interior da Itália, enquanto Campione d &a
ario é ) é éicialmente,ública (a, é umma freública dealentoá deário doizada pel Brasro daameró, Uni.\n Repe da comaz partonteira com oa, queíça e E�rearia, �spanâinania,o longo do paente.\n suir do doe em � deade de Europaínsula,áliaa, queâlia, Itãoia, S fras principaiores dohas, �,iterrâno, e oaiso mras ilhas door.azç- santo do paório.aliano.\n principados Unes do Portugal Marino e S Brasilaano,ão aadas em territ do Europaálic, queanto ao,asquos; Repá & a paéminist doaliano. Europaíça.\n paório It
learn.blurr_generate('Itália ( ), oficialmente República Italiana', max_length=100, do_sample=True, top_k=25)
[' Itália ( ), oficialmente República Italiana , que o estudante do Brasil , é um município da Beira e suporte com o Brasileiro de Portugal em 1824 . No Brasil , ao município da Beira é o distrito de Beira . A sua capital da Beira é o seu capital , do nome da América do Sul e do nordeste']
Summary
This example demonstrates how to train a causal language model where the raw data examples are in individual files (similar to how the standard wikitext-103 is defined). We also defined a custom splitter function so as to put all the files under /valid as part of the validation set and all the files under /train in the training set.